|
Postdoc Scholar at UC Berkeley. Doctor of Philosophy at Peking University. Email: ruihai [at] berkeley.edu |

|
News
|
|

|
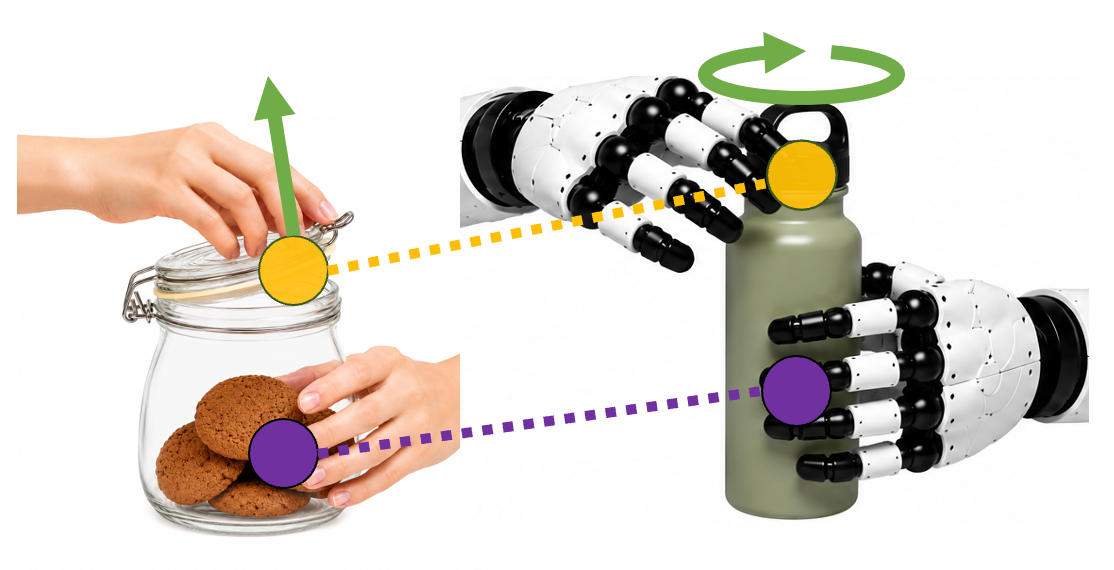
LeHome Team, Ruihai Wu+ ICRA 2026 Best Poster Award at IROS 2025 Workshop on Robotic Manipulation of Deformable Objects Poster at NVIDIA GTC 2026 project page / paper / code / video / LeHome Challenge at ICRA 2026 We propose LeHome, a framework that is able to simulate 6 categories of deformable objects in household scenarios with low-cost robots. |
|
Jinxian Zhou*, Ruihai Wu*, Yiwei Liu, Yiwen Hou, Xunzhe Zhou, Checheng Yu, Lin Shao ICRA 2026 Best Paper Award Finalist Best Paper Award on Best Paper Award on Robot Manipulation and Locomotion Finalist project page / paper / code / video For the generalization and stable coordination of complex bimanual manipulation tasks, we propose to use correspondence from foundation models for efficient adaptation of affordance and action. |

|
Jasper Lu, Zhenhao Shen, Yuanfei Wang, Shugao Liu, Shengqiang Xu, Shawn Xie, Kyle Xu, Feng Jiang, Jade Yang, Chen Xie, Ruihai Wu+ Best Paper Award at ICRA 2026 Workshop on Generative Digital Twins for Real2Sim and Sim2Real Transfer in Robotics project page / paper / code / video WorldComposer is a novel approach for generative high-fidelity simulation with digital cousins for generalizable robot learning and evaluation. |
|
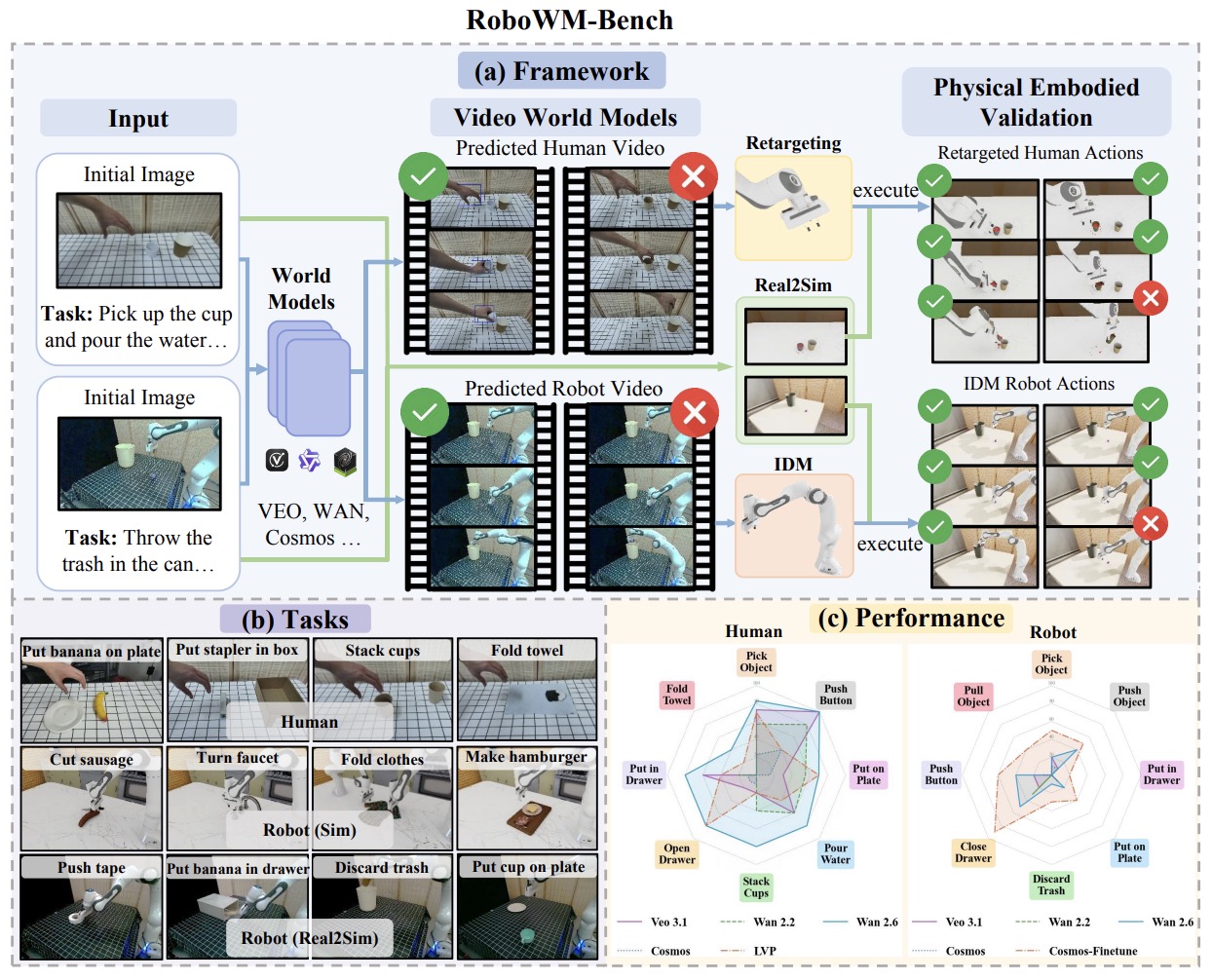
Feng Jiang, Yang Chen, Kyle Xu, Yuchen Liu, Haifeng Wang, Zhenhao Shen, Jasper Lu, Shengze Huang, Yuanfei Wang, Chen Xie, Ruihai Wu+ Best Paper Award at CVPR 2026 Workshop on World Models Meet Active Sensing and Closed-Loop Planning project page / paper / code RoboWM-Bench is a manipulation-centric benchmark for embodiment-grounded evaluation of video world models. It converts generated behaviors from both human-hand and robotic manipulation videos into embodied action sequences and validates them through robotic execution. |
|
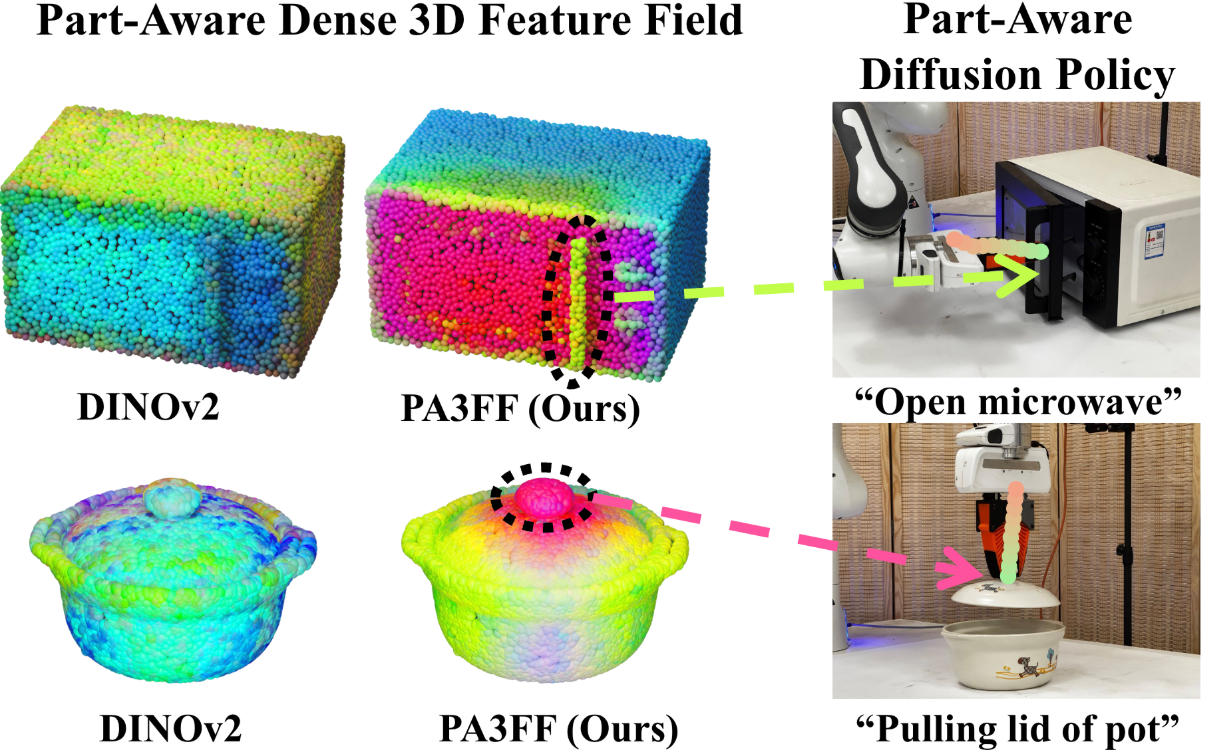
Yue Chen, Muqing Jiang, Kaifeng Zheng, Jiangqi Liang, Chenrui Tie, Haoran Lu, Ruihai Wu+ Hao Dong+, ICLR 2026 Best Paper Runner-up Award at CVPR 2026 Workshop on 3D-LLM/VLA project page / paper / code / video When lifting 2D features to geometry-profound 3D space, challenges arise, such as long runtimes, multi-view inconsistencies, and low spatial resolution with insufficient geometric information. Therefore, we propose Part-Aware 3D Feature Field (PA3FF), a novel dense 3D feature with part awareness for generalizable articulated object manipulation. |
|
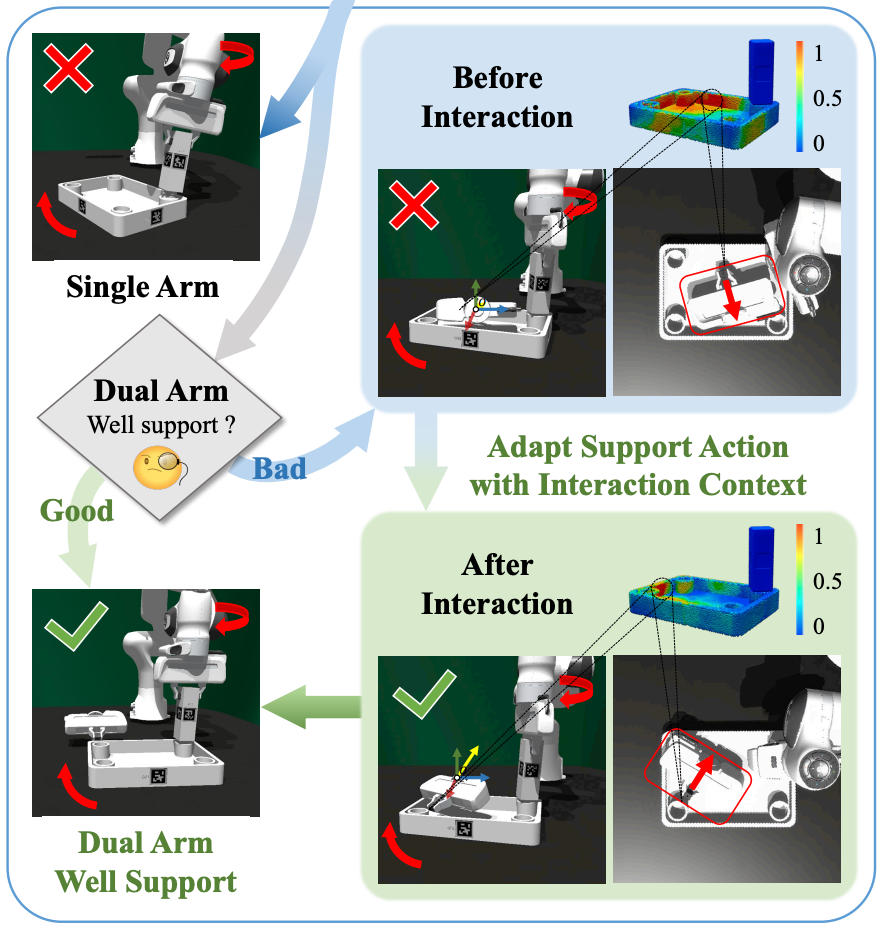
Jiaqi Liang, Yue Chen, Qize Yu, Yan Shen, Haipeng Zhang, Hao Dong, Ruihai Wu+ AAAI 2026 (Oral presentation) project page / paper / code / video Furniture assembly requires precise dual-arm coordination where one arm manipulates parts while the other provides collaborative support and stabilization. We propose A3D, a framework which adaptively identifies optimal support and stabilization locations on furniture parts. |
|
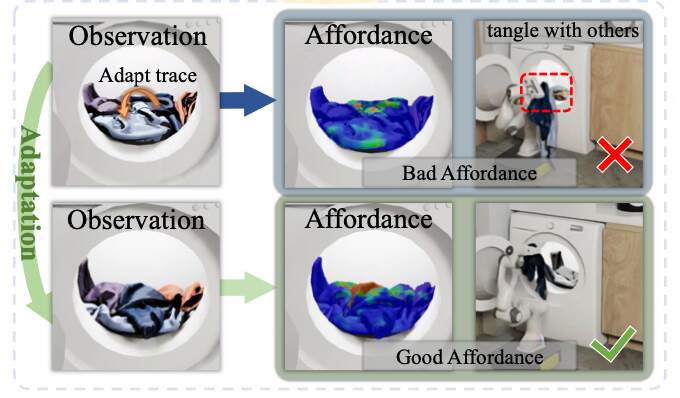
Ruihai Wu*, Ziyu Zhu*, Yuran Wang*, Yue Chen, Jiarui Wang, Hao Dong CVPR 2025 Best Poster Finalist at IROS 2025 Workshop on Robotic Manipulation of Deformable Objects project page / paper / code / video We propose to learn point-level affordance to model the complex space and multi-modal manipulation candidates of garment piles, with novel designs for the awareness of garment geometry, structure, inter-object relations, and further adaptation. |

|
Yan Shen*, Ruihai Wu*, Yubin Ke, Xinyuan Song, Zeyi Li, Xiaoqi Li, Hongwei Fan, Haoran Lu, Hao Dong ICML 2025 Distinguished Workshop Paper Award at IROS 2025 Workshop on Frontiers in Dynamic, Intelligent, and Adaptive Multi-arm Manipulation project page / paper / code / video We exploit the geometric generalization of point-level affordance, learning affordance aware of bimanual collaboration in geometric assembly with long-horizon action sequences. |
|
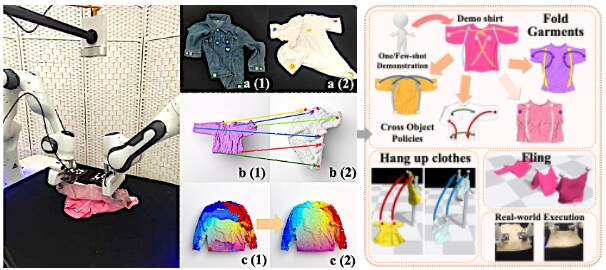
Ruihai Wu*, Haoran Lu*, Yiyan Wang, Yubo Wang, Hao Dong CVPR 2024 Nomination (top3) of Outstanding Youth Paper Award at China Embodied AI Conference (CEAI) 2025 Spotlight Presentation at ICRA 2024 Workshop on Deformable Object Manipulation project page / paper / code / video We propose to learn dense visual correspondence for diverse garment manipulation tasks with category-level generalization using only one- or few-shot human demonstrations. |

|
Ruihai Wu*, Kai Cheng*, Yan Shen, Chuanruo Ning, Guanqi Zhan, Hao Dong NeurIPS 2023 project page / paper / code / video We explore the task of manipulating articulated objects within environment constraints and formulate the task of environment-aware affordance learning for manipulating 3D articulated objects, incorporating object-centric per-point priors and environment constraints. |
|
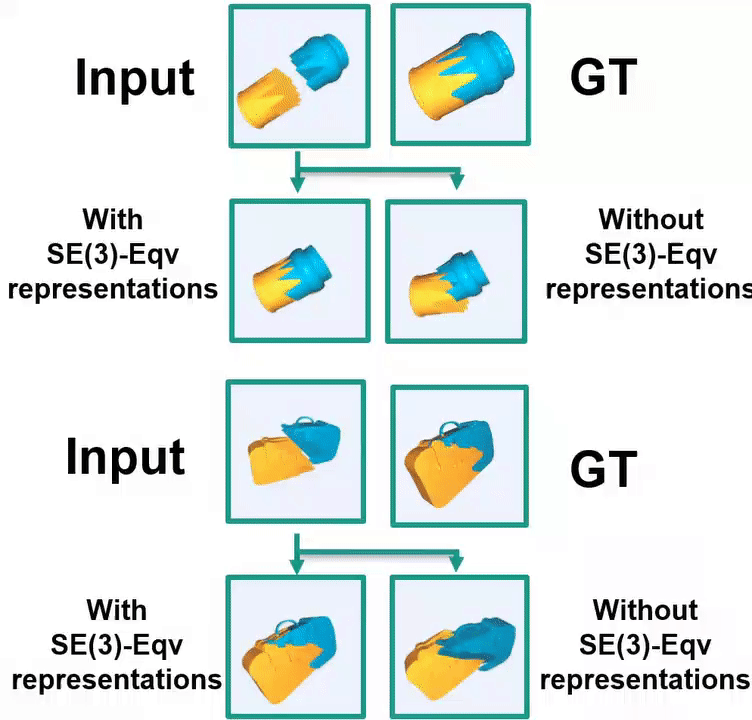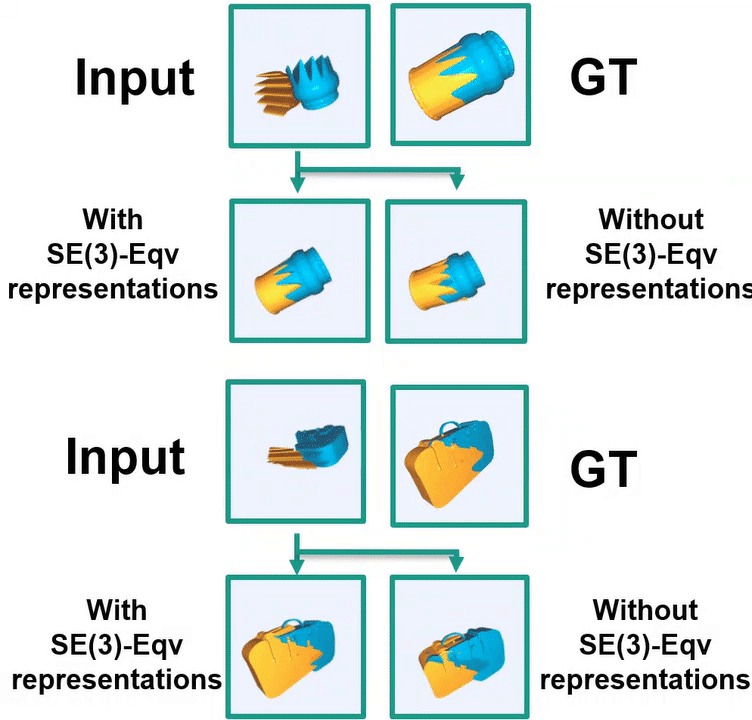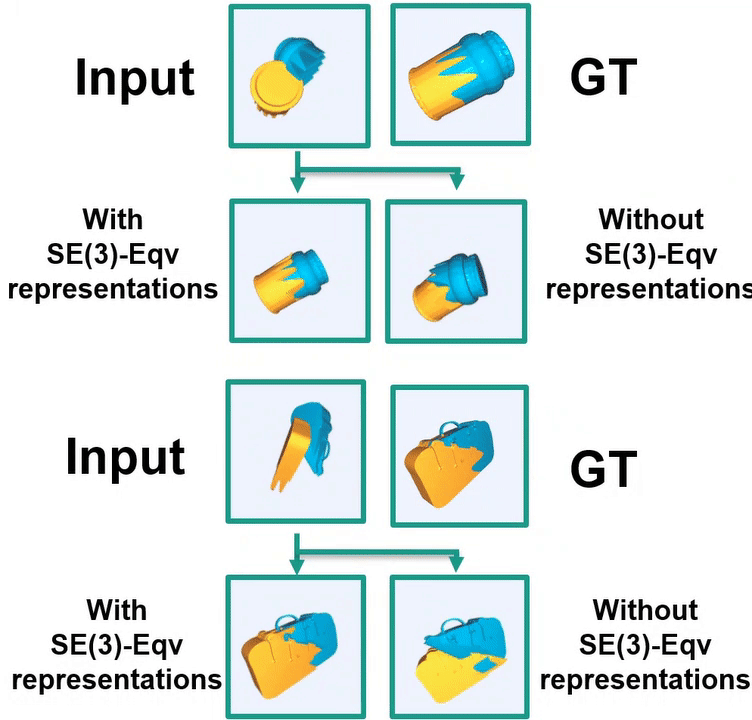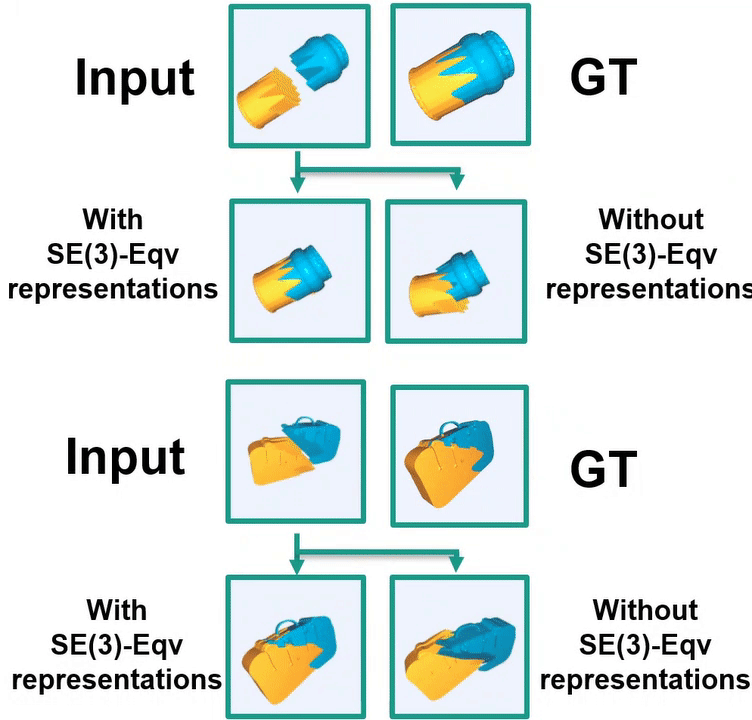
Ruihai Wu*, Chenrui Tie*, Yushi Du, Yan Shen, Hao Dong ICCV 2023 project page / paper / code / video We study geometric shape assembly by leveraging SE(3) Equivariance, which disentangles poses and shapes of fractured parts. |
|
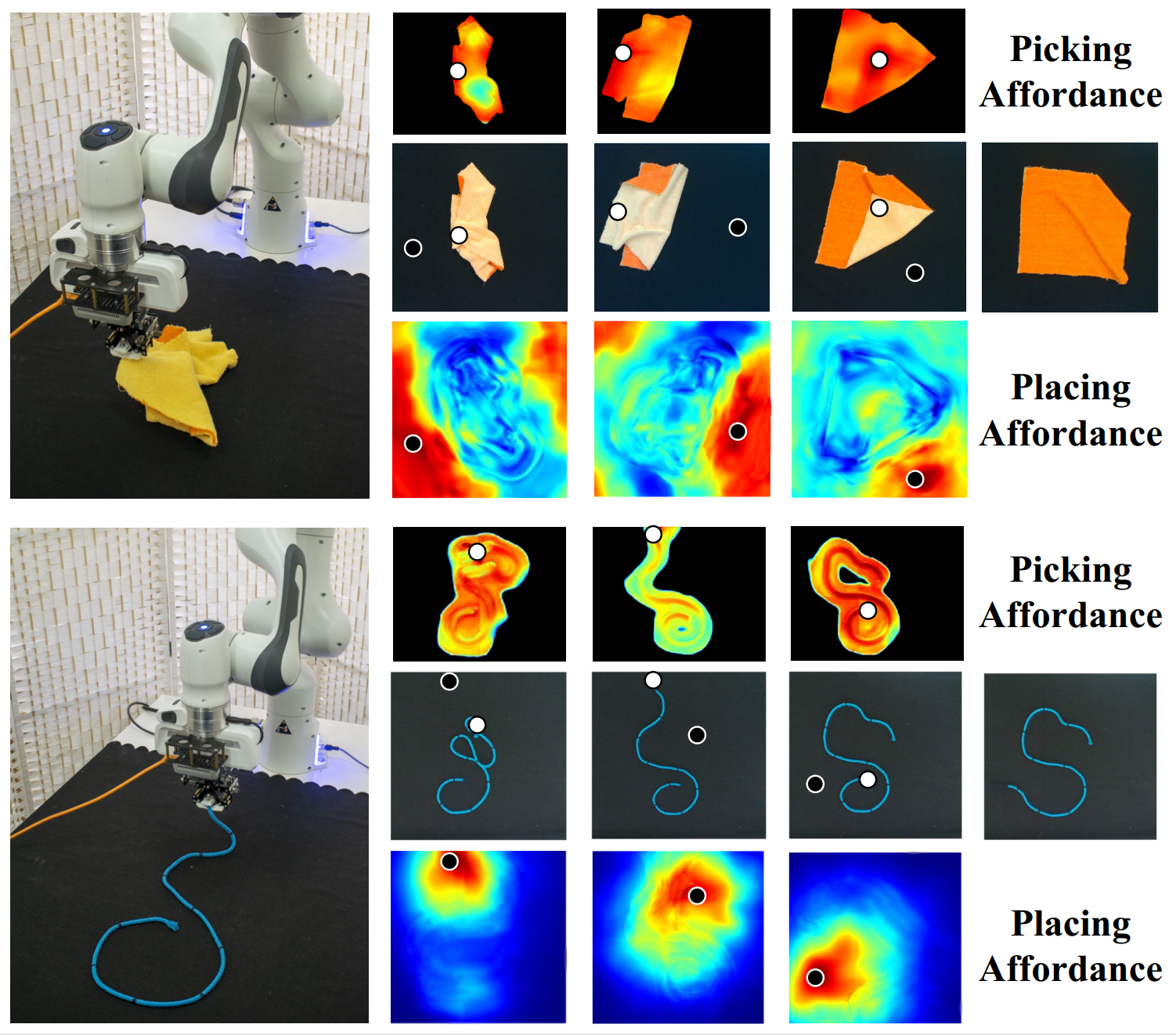
Ruihai Wu*, Chuanruo Ning*, Hao Dong ICCV 2023 project page / paper / code / video / video (real world) We study deformable object manipulation using dense visual affordance, with generalization towards diverse states, and propose a novel kind of foresightful dense affordance, which avoids local optima by estimating states’ values for longterm manipulation. |

|
Ruihai Wu*, Yan Zhao*, Kaichun Mo*, Zizheng Guo, Yian Wang, Tianhao Wu, Qingnan Fan, Xuelin Chen, Leonidas J. Guibas, Hao Dong ICLR 2022 Shortlist (top40 among AI papers 2022-2025) of Youth Outstanding Paper Award at World AI Conference (WAIC) 2025 project page / paper / code / video We study dense geometry-aware, interaction-aware, and task-aware visual action affordance and trajectory proposals for manipulating articulated objects. |

|
Ruihai Wu, Kehan Xu, Chenchen Liu, Nan Zhuang, Yadong Mu AAAI 2020 (Oral presentation) paper We propose localize-assemble-predicate network (LAP-Net), decomposing visual relation detection (VRD) into three sub-tasks to tackle the long-tailed data distribution problem. |
{kind=link}
{kind=link}
|
|
|
|
A deep learning and reinforcement learning library designed for researchers and engineers. ACM MM Best Open Source Software Award, 2017. I am one of the main contributors of its 2.0 version. GitHub / star (7000+) / fork (1600+) / contributors |
|
Umbrella research project behind Ideas in Excel of Microsoft Office 365 product. Intelligent feature announced at Microsoft Ignite Conference and released on March, 2019. Star of tomorrow excellent intern, 2019. project page |
|
|

|
Garment Manipulation Skill Learning in Household Scenarios Leading Organizer report (Ilya, 2nd Place) / report (Aakash, 3rd Place) |

|
Challenge on Manipulation Skill Learning With Vision and Tactile Sensing Champion in Track2 Team leader |

|
This challenge focuses on developing robust locomotion controllers for humanoid robots to navigate complex, unstructured terrains - a critical capability for real-world deployment in homes, disaster zones, and natural environments. Second Place (Second Prize) |
|
|
|
Reviewer: ICCV, CVPR, ICLR, NeurIPS, RSS, ICRA, RA-L, T-RO, T-Mech, TVCG
Workshop Organizer: ICCV Workshop on Category-Level Object Pose Estimation in the Wild 2025, IROS Workshop on Bimanual Manipulation 2026, IROS Workshop on Deformable Objects Manipulation 2026 Challenge Organizer: LeHome Challenge at ICRA 2026 Student Committee Member: ARTS Volunteer: WINE 2020 |
|
|
|
Teaching Assistant:
Deep Generative Models, 2020, 2022 Guest Lecturer: Frontier Computing Research Practice (Course of Open Source Development), 2024 Introduction to Computing (Course of Dynamic Programming), 2024 |
|
|
|
Best Paper Finalist, ICRA, 2026 Best Paper Award, CVPR WMAS Workshop, 2026 Best Paper Award, ICRA Generative Digital Twin Workshop, 2026 Best Paper Runner-up Award, CVPR 3D-LLM/VLA Workshop, 2026 Best Poster Award and 2 Finalists, IROS ROMADO Workshop, 2025 Champion (team leader), ManiSkill-ViTac Challenge (presented at ICRA ViTac Workshop), 2025 Doctoral Consortium, CVPR, 2025 Doctoral Consortium (Oral Highlights), ICRA, 2025 Shortlist (top40 among AI papers 2022-2025), Youth Outstanding Paper Award of World AI Conference (WAIC), 2025 Nomination Award (top3), Outstanding Young Scholar Paper Award of China Embodied AI Conference (CEAI), China, 2025 ByteDance Scholarship, China and Singapore, 2024 Nomination Award (top8), ARTS Scholarship, China, 2024 Rising Star Nomination, Outstanding Student Workshop Speaker (top8), China3DV, 2024/2025 Nomination, Apple AI/ML Scholar Fellowship, WorldWide, 2024 Excellent Graduate, Peking University, 2020 (undergrad), 2025 (Ph.D.) National Scholarship, May Fourth Scholarship, Merit Student, Research and Academic Excellence Award, Peking University Star of Tomorrow Excellent Intern, Microsoft Research Asia, 2019 Bronze medal in National Olympiad in Informatics (NOI), China Computer Federation, 2015 First prize in National Olympiad in Informatics in Provinces (NOIP), China Computer Federation, 2013, 2014, 2015 |
|
Website template comes from Jon Barron
Last update: July, 2026 |