|
I obtained PhD degree at Center on Frontiers of Computing Studies (CFCS) at Peking University , advised by Professor Hao Dong. My research interests include 3D vision and robotics. Email: wuruihai [at] pku.edu.cn |

|
|
|
|
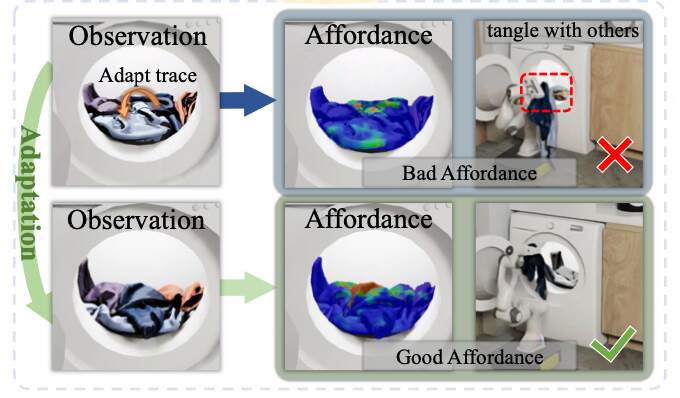
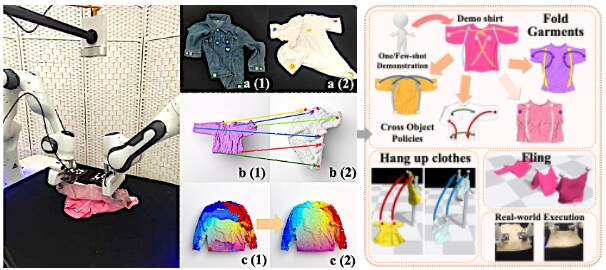
Ruihai Wu*, Ziyu Zhu*, Yuran Wang*, Yue Chen, Jiarui Wang, Hao Dong CVPR 2025 Best Poster Finalist at IROS 2025 Workshop on Robotic Manipulation of Deformable Objects project page / paper / code / video We propose to learn point-level affordance to model the complex space and multi-modal manipulation candidates of garment piles, with novel designs for the awareness of garment geometry, structure, inter-object relations, and further adaptation. |

|
Yan Shen*, Ruihai Wu*, Yubin Ke, Xinyuan Song, Zeyi Li, Xiaoqi Li, Hongwei Fan, Haoran Lu, Hao Dong ICML 2025 Distinguished Workshop Paper Award at IROS 2025 Workshop on Frontiers in Dynamic, Intelligent, and Adaptive Multi-arm Manipulation project page / paper / code / video We exploit the geometric generalization of point-level affordance, learning affordance aware of bimanual collaboration in geometric assembly with long-horizon action sequences. |
|
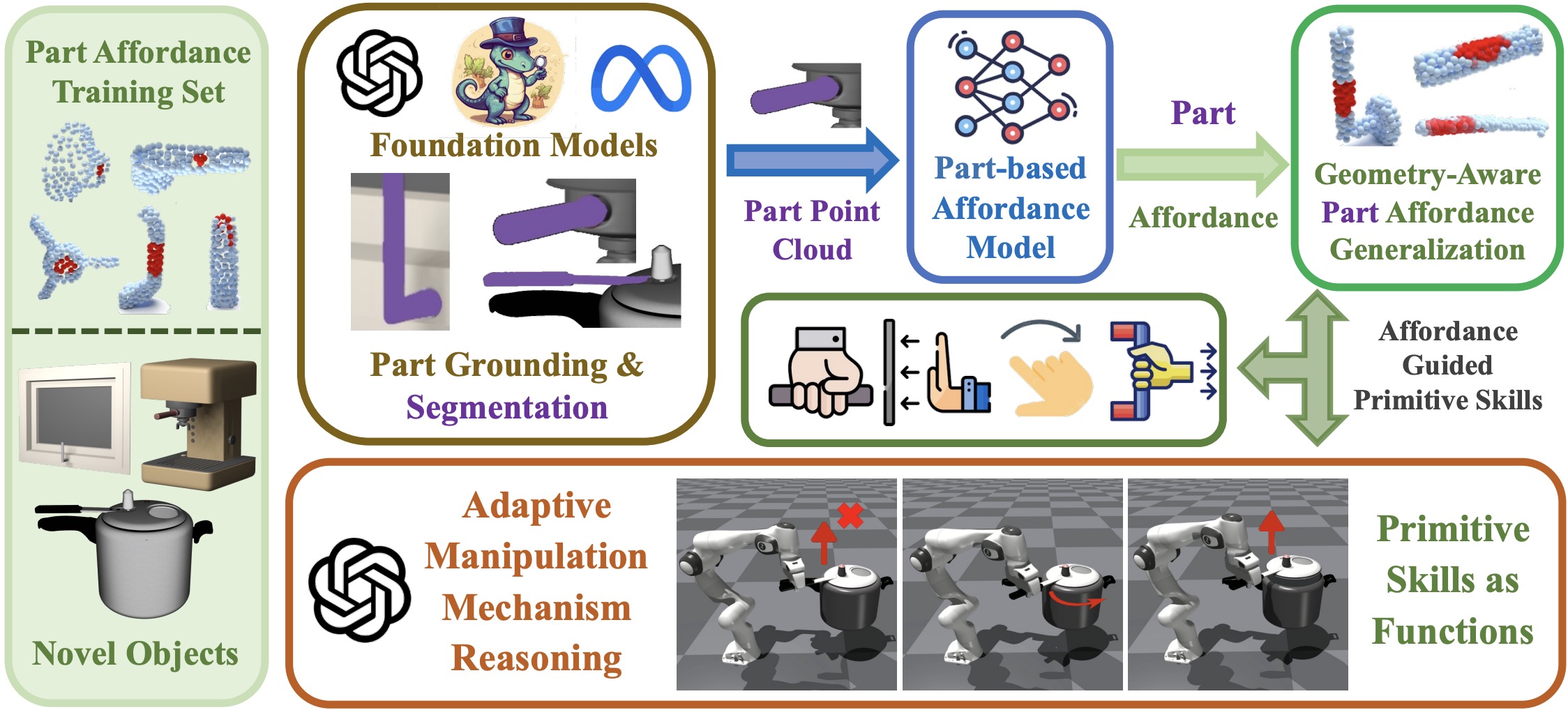
Xiaojie Zhang*, Yuanfei Wang*, Ruihai Wu*, Kunqi Xu, Yu Li, Hao Dong, Zhaofeng He ICCV 2025 project page / paper / code (coming soon) / video (coming soon) We propose AdaRPG, a novel framework that leverages foundation models to extract object parts, which exhibit greater local geometric similarity than entire objects, thereby enhancing visual affordance generalization for functional primitive skills. |
|
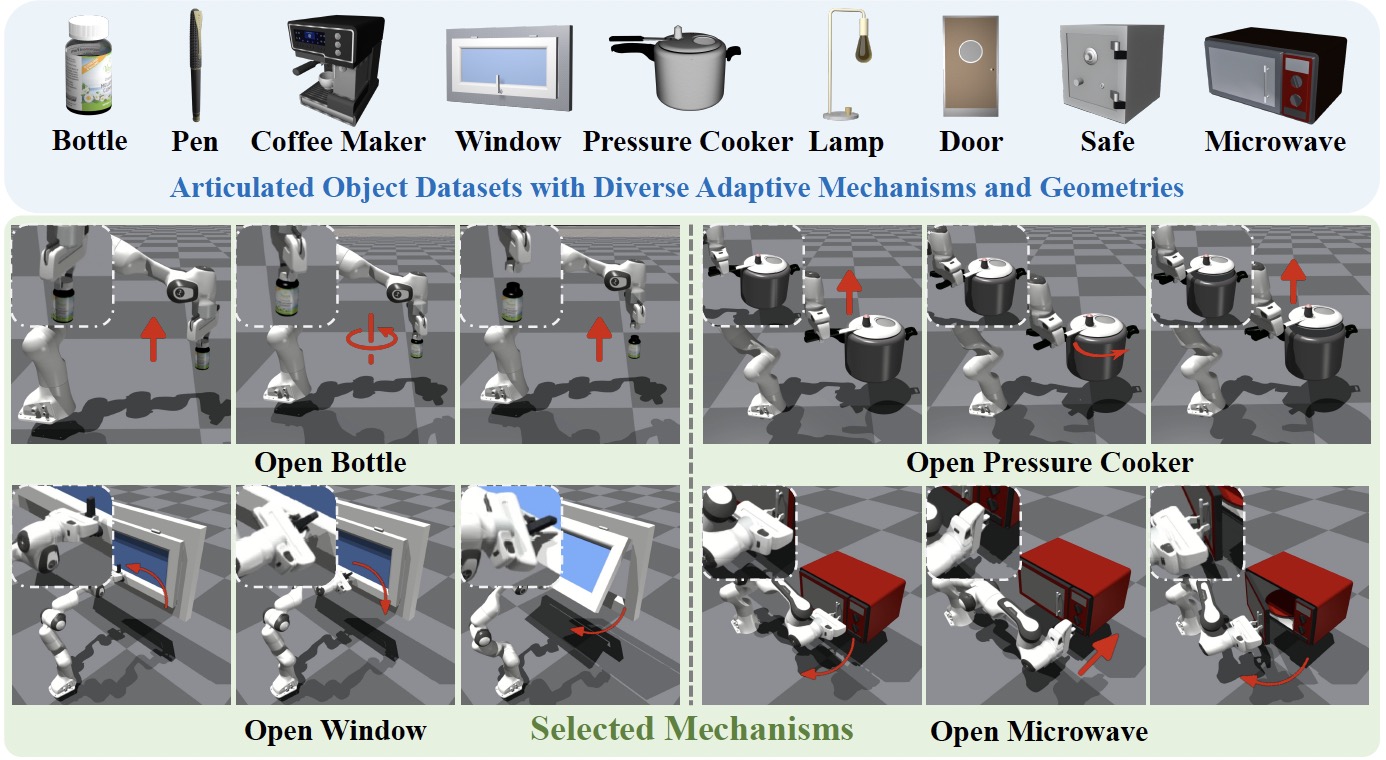
Yuanfei Wang*, Xiaojie Zhang*, Ruihai Wu*, Yu Li, Yan Shen, Mingdong Wu, Zhaofeng He, Yizhou Wang, Hao Dong ICLR 2025 project page / paper / code / video We propose adaptive assets, environment and policy to manipulate articulated objects with diverse mechanisms. |

|
Chenrui Tie*, Yue Chen*, Ruihai Wu*, Boxuan Dong, Zeyi Li, Chongkai Gao, Hao Dong ICLR 2025 project page / paper / code / video We theoretically extend equivariant Markov kernels and simplify the condition of equivariant diffusion process, thereby significantly improving training efficiency for trajectory-level SE(3) equivariant diffusion policy in an end-to-end manner. |
|
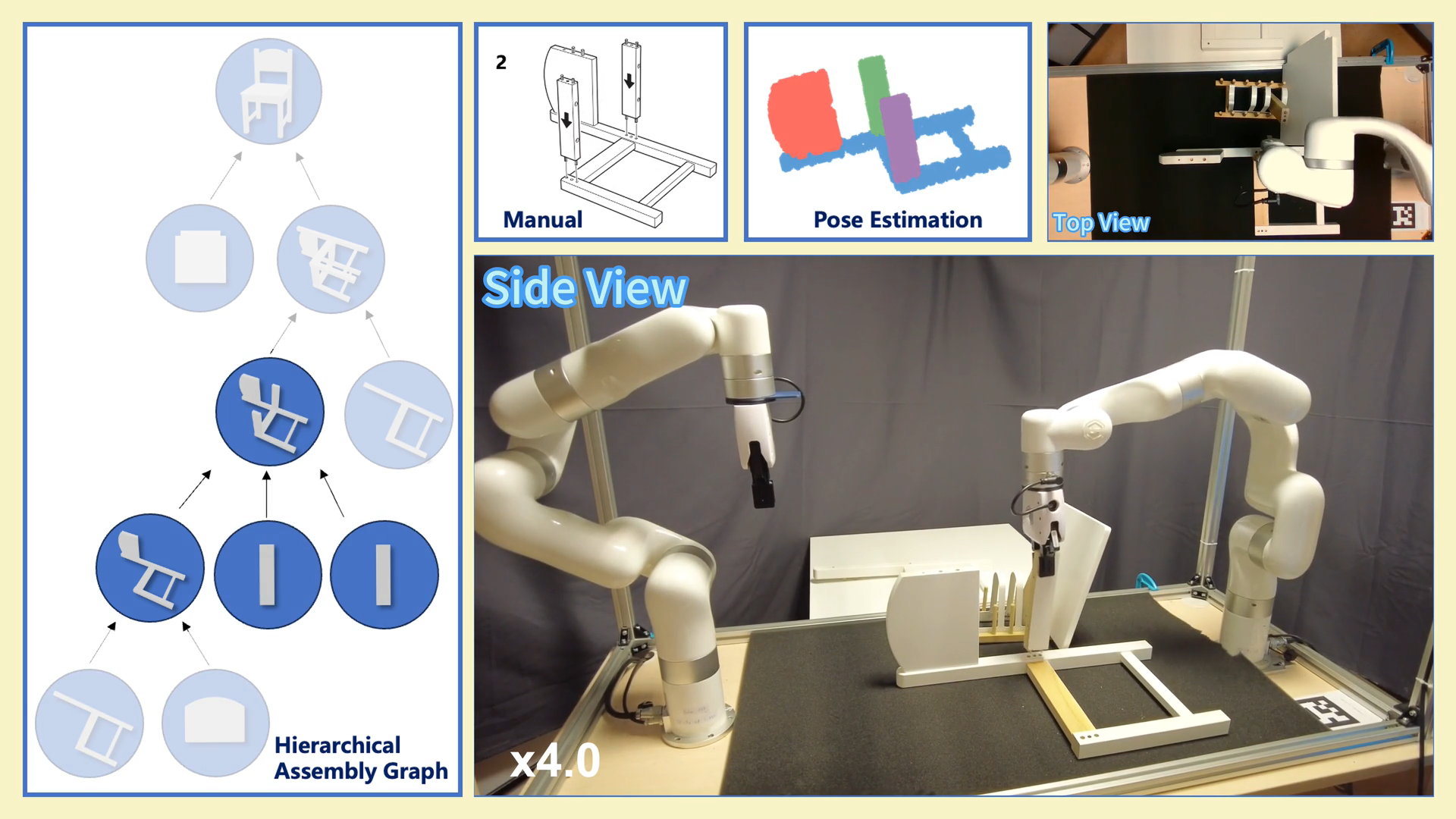
Chenrui Tie*, Shengxiang Sun*, Jinxuan Zhu, Yiwei Liu, Jingxiang Guo, Yue Hu, Haonan Chen, Junting Chen, Ruihai Wu, Lin Shao RSS 2025 project page / paper / code / video We propose a novel framework that enables VLM to understand human-designed manuals and acquire robotic skills for furniture assembly tasks. |

|
RoboVerse Team RSS 2025 project page / paper / code / video We propose RoboVerse, a comprehensive framework for advancing robotics through a simulation platform, synthetic dataset, and unified benchmarks. Its MetaSim infrastructure abstracts diverse simulators into a universal interface, ensuring interoperability and extensibility. |
|
Ruihai Wu*, Haoran Lu*, Yiyan Wang, Yubo Wang, Hao Dong CVPR 2024 Nomination (top3) of Outstanding Youth Paper Award at China Embodied AI Conference (CEAI) 2025 Spotlight Presentation at ICRA 2024 Workshop on Deformable Object Manipulation project page / paper / code / video We propose to learn dense visual correspondence for diverse garment manipulation tasks with category-level generalization using only one- or few-shot human demonstrations. |
|
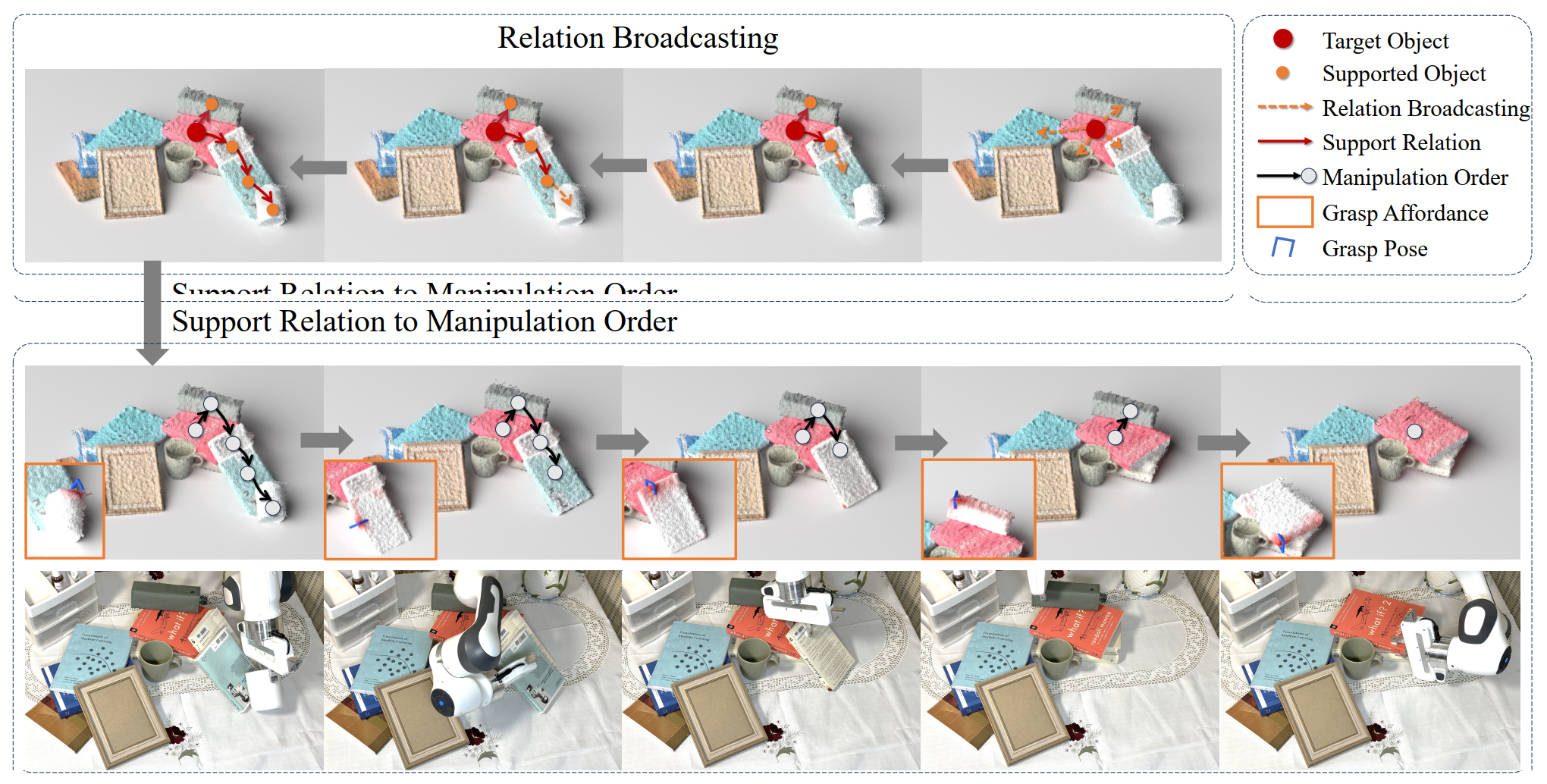
Yitong Li*, Ruihai Wu*, Haoran Lu, Chuanruo Ning, Yan Shen, Guanqi Zhan, Hao Dong RSS 2024 Best Poster Award at PKU AI Tech Day 2024 project page / paper / code / video In this paper, we study retrieving objects in complicated clutters via a novel method of recursively broadcasting the accurate local dynamics to build a support relation graph of the whole scene, which largely reduces the complexity of the support relation inference and improves the accuracy. |

|
Haoran Lu*, Ruihai Wu*, Yitong Li*, Sijie Li, Ziyu Zhu*, Chuanruo Ning, Yan Shen, Longzan Luo, Yuanpei Chen, Hao Dong NeurIPS 2024 Spotlight Presentation at ICRA 2024 Workshop on Deformable Object Manipulation project page / paper / code / video We present GarmentLab, a benchmark designed for garment manipulation within realistic 3D indoor scenes. Our benchmark encompasses a diverse range of garment types, robotic systems and manipulators including dexterous hands. The multitude of tasks included in the benchmark enables further exploration of the interactions between garments, deformable objects, rigid bodies, fluids, and avatars. |

|
Kairui Ding, Boyuan Chen, Ruihai Wu, Yuyang Li, Zongzheng Zhang, Huan-ang Gao, Siqi Li, Yixin Zhu, Guyue Zhou, Hao Dong, Hao Zhao IROS 2024 Best Poster Finalist at IROS 2024 Workshop on Embodied Navigation to Movable Objects project page / paper / code / video PreAfford is a novel pre-grasping planning framework that improves adaptability across diverse environments and object by utilizing point-level affordance representation and relay training. Validated on the ShapeNet-v2 dataset and real-world experiments, PreAfford offers a robust solution for manipulating ungraspable objects with two-finger grippers. |
|
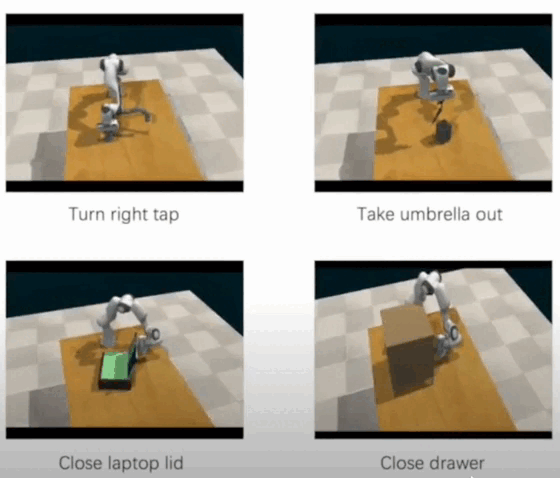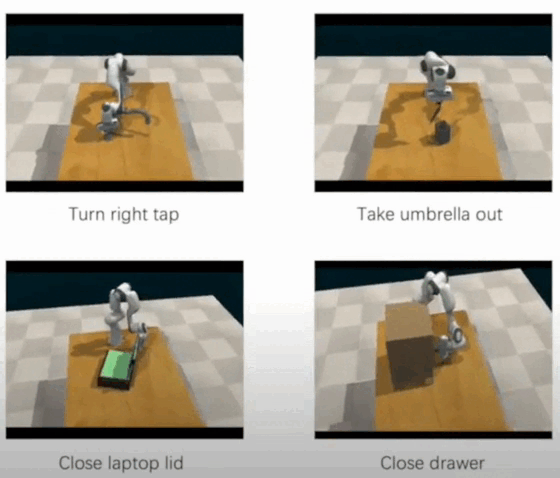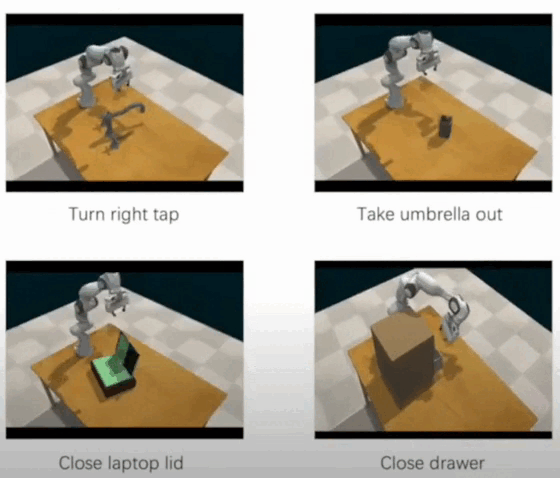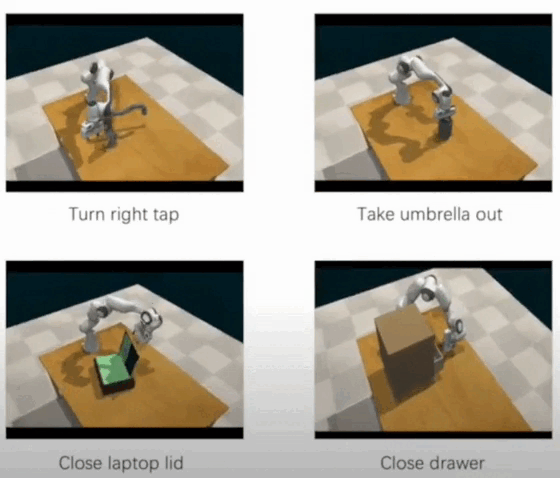
Ran Xu*, Yan Shen*, Xiaoqi Li, Ruihai Wu, Hao Dong RA-L 2024 project page / paper / video We introduce a comprehensive benchmark, NaturalVLM, comprising 15 distinct manipulation tasks, containing over 4500 episodes meticulously annotated with fine-grained language instructions. Besides, we propose a novel learning framework that completes the manipulation task step-by-step according to the fine-grained instructions. |

|
Ruihai Wu*, Kai Cheng*, Yan Shen, Chuanruo Ning, Guanqi Zhan, Hao Dong NeurIPS 2023 project page / paper / code / video We explore the task of manipulating articulated objects within environment constraints and formulate the task of environment-aware affordance learning for manipulating 3D articulated objects, incorporating object-centric per-point priors and environment constraints. |
|
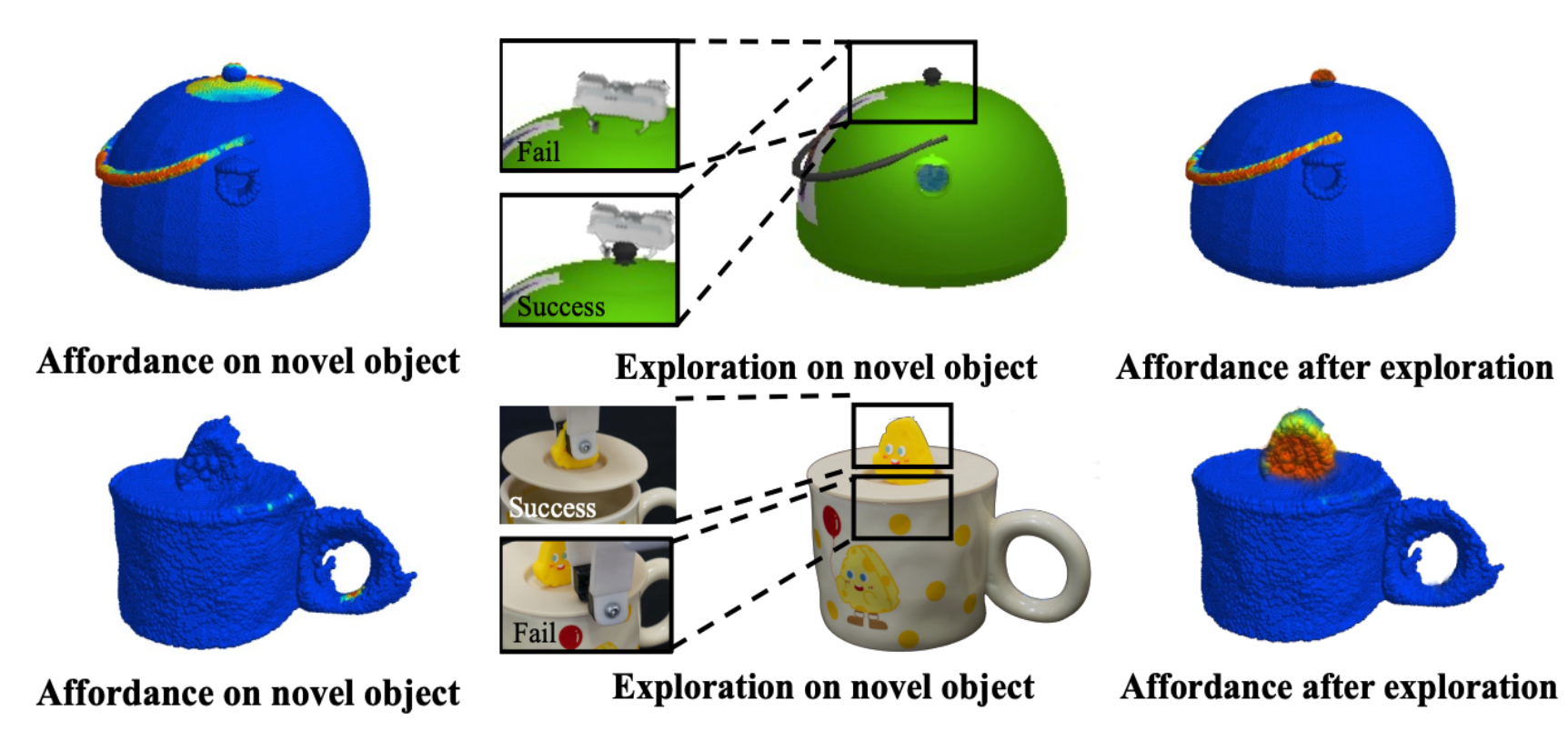
Chuanruo Ning, Ruihai Wu, Haoran Lu, Kaichun Mo, Hao Dong NeurIPS 2023 project page / paper / code / video We introduce an affordance learning framework that effectively explores novel categories with minimal interactions on a limited number of instances. Our framework explicitly estimates the geometric similarity across different categories, identifying local areas that differ from shapes in the training categories for efficient exploration while concurrently transferring affordance knowledge to similar parts of the objects. |
|
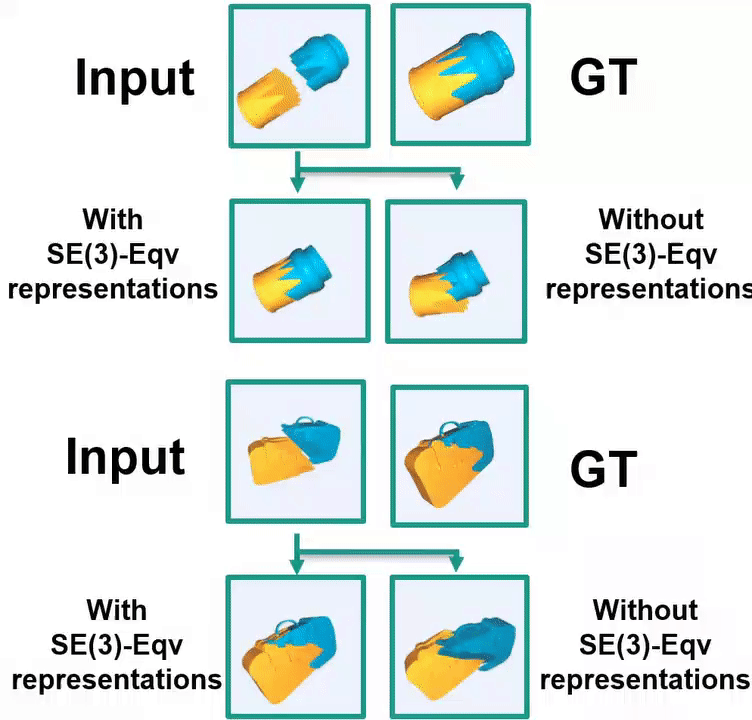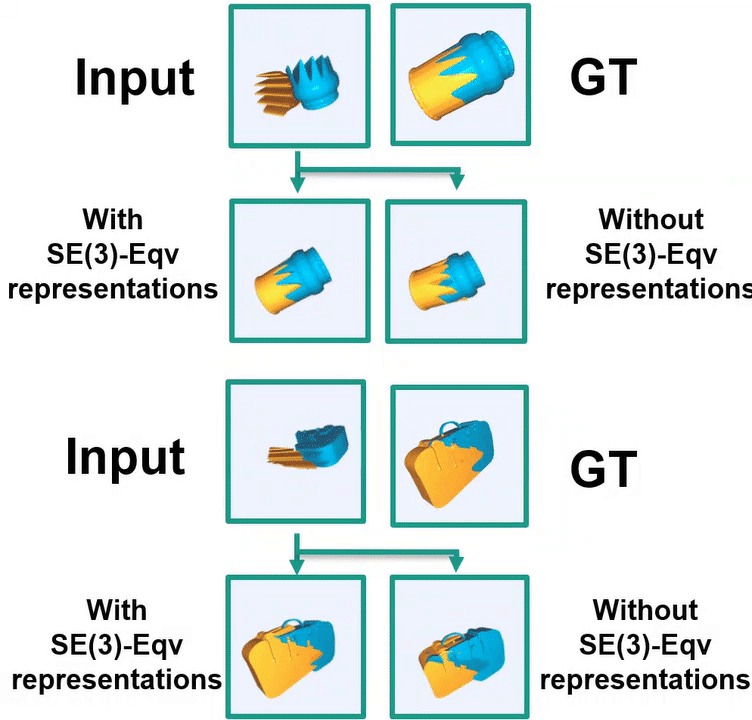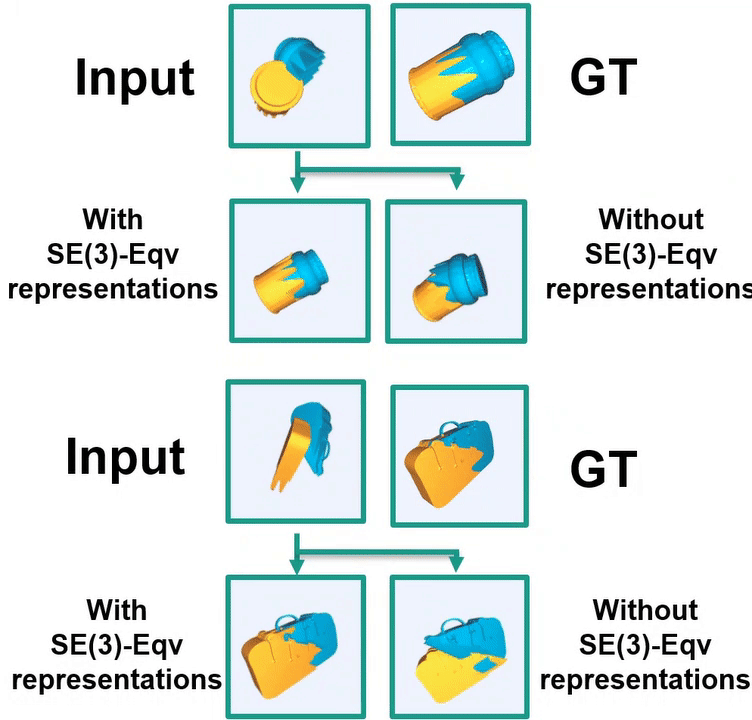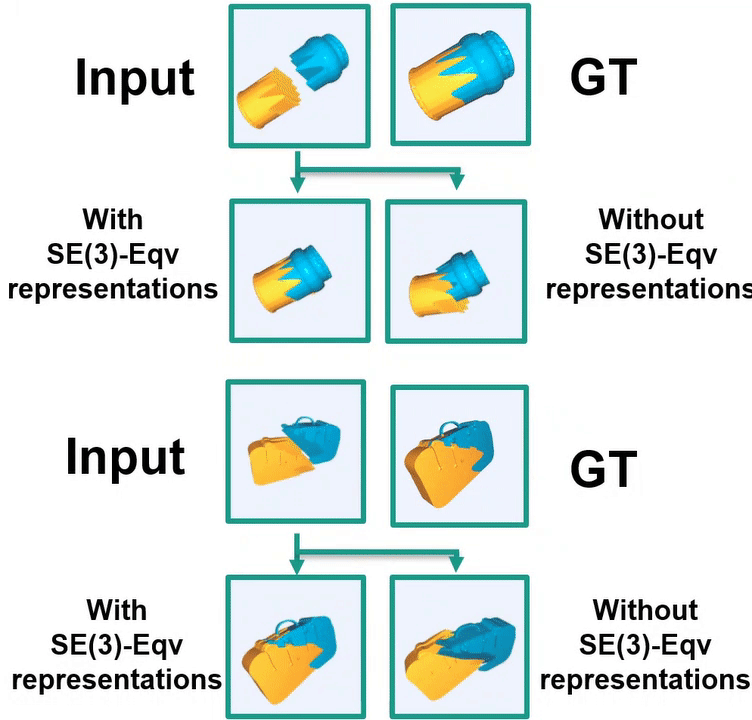
Ruihai Wu*, Chenrui Tie*, Yushi Du, Yan Shen, Hao Dong ICCV 2023 project page / paper / code / video We study geometric shape assembly by leveraging SE(3) Equivariance, which disentangles poses and shapes of fractured parts. |
|
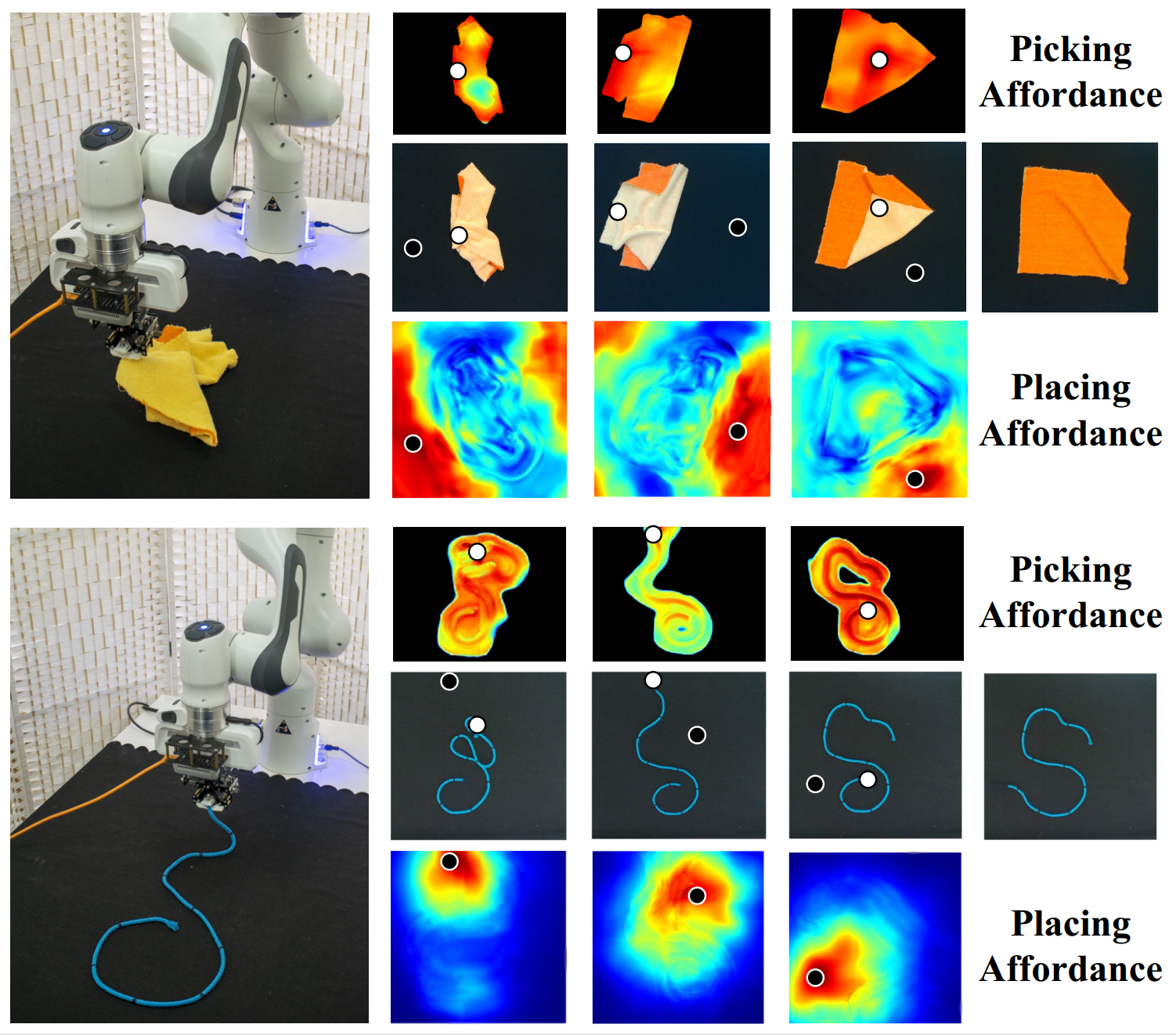
Ruihai Wu*, Chuanruo Ning*, Hao Dong ICCV 2023 project page / paper / code / video / video (real world) We study deformable object manipulation using dense visual affordance, with generalization towards diverse states, and propose a novel kind of foresightful dense affordance, which avoids local optima by estimating states’ values for longterm manipulation. |
|
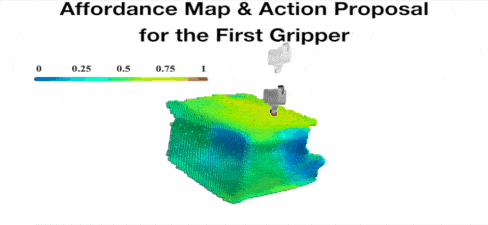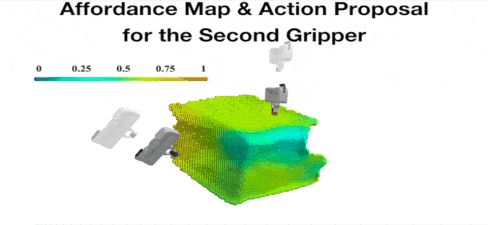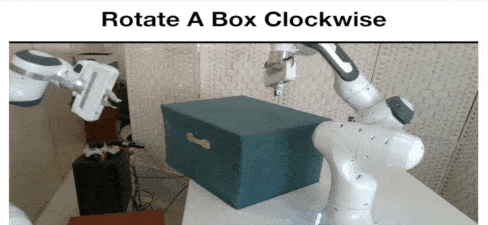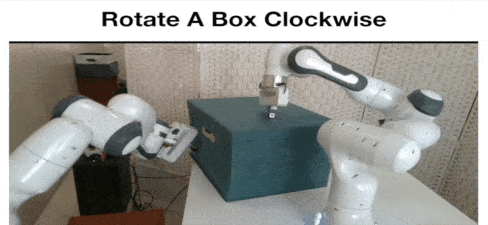
Yan Zhao*, Ruihai Wu*, Zhehuan Chen, Yourong Zhang, Qingnan Fan, Kaichun Mo, Hao Dong ICLR 2023 project page / paper / code / video We study collaborative affordance for dual-gripper manipulation. The core is to reduce the quadratic problem for two grippers into two disentangled yet interconnected subtasks. |
|
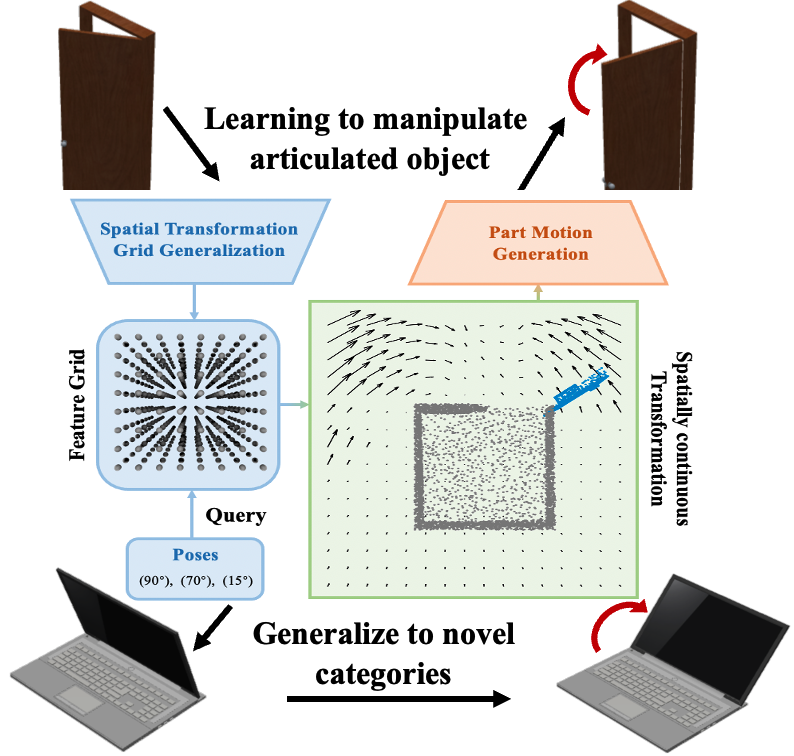
Yushi Du*, Ruihai Wu*, Yan Shen, Hao Dong BMVC 2023 project page / paper / code / video We introduce a novel framework that explicitly disentangles the part motion of articulated objects by predicting the movements of articulated parts by utilizing spatially continuous neural implicit representations. |

|
Yian Wang*, Ruihai Wu*, Kaichun Mo*, Jiaqi Ke, Qingnan Fan, Leonidas J. Guibas, Hao Dong ECCV 2022 project page / paper / code / video We study performing very few test-time interactions for quickly adapting the affordance priors to more accurate instance-specific posteriors. |

|
Ruihai Wu*, Yan Zhao*, Kaichun Mo*, Zizheng Guo, Yian Wang, Tianhao Wu, Qingnan Fan, Xuelin Chen, Leonidas J. Guibas, Hao Dong ICLR 2022 Shortlist (top40 among AI papers from 2022-2025) of Youth Outstanding Paper Award at World AI Conference (WAIC) 2025 project page / paper / code / video We study dense geometry-aware, interaction-aware, and task-aware visual action affordance and trajectory proposals for manipulating articulated objects. |
|
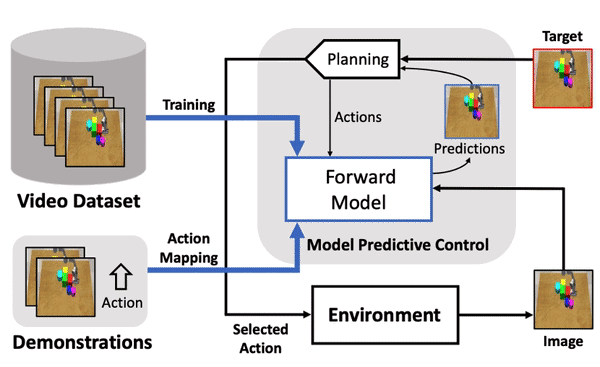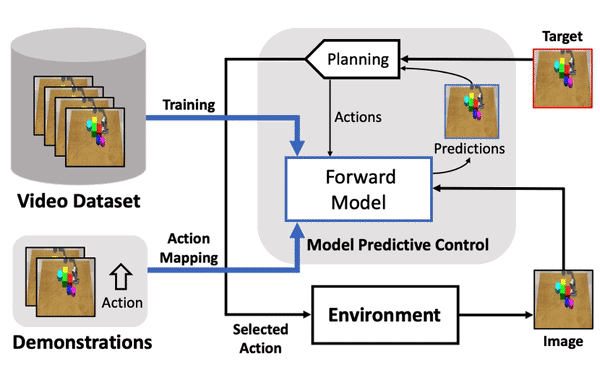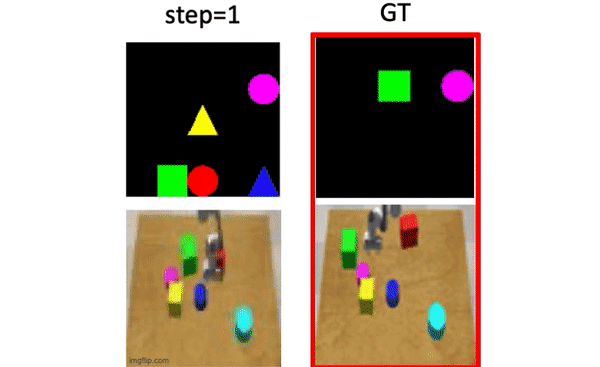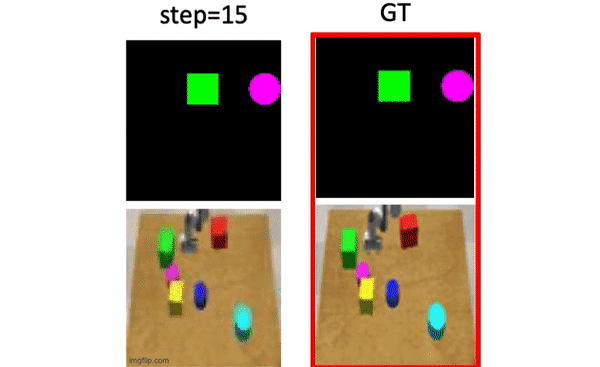
Haoqi Yuan*, Ruihai Wu*, Andrew Zhao*, Haipeng Zhang, Zihan Ding, Hao Dong IROS 2021 project page / paper / code We train a forward model from video data only, via disentangling the motion of controllable agent to model the transition dynamics. |
|
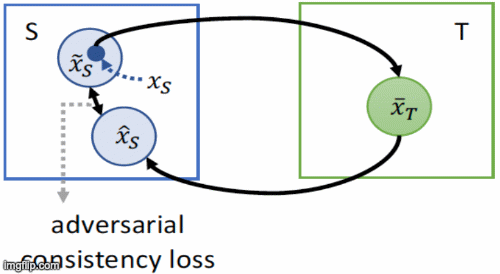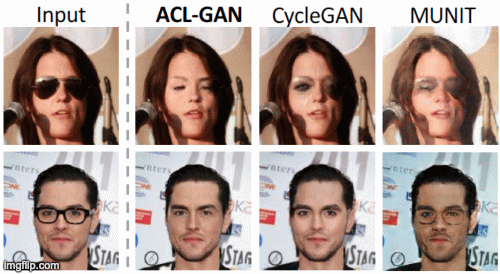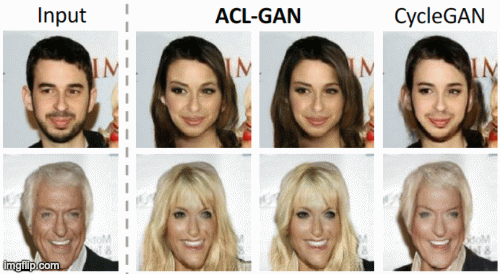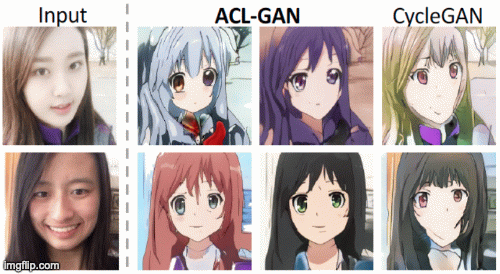
Yihao Zhao, Ruihai Wu, Hao Dong ECCV 2020 project page / paper / code / video We propose adversarial consistency loss for image-to-image translation that does not require the translated image to be translated back to the source image. |

|
Ruihai Wu, Kehan Xu, Chenchen Liu, Nan Zhuang, Yadong Mu AAAI 2020 (Oral presentation) paper We propose localize-assemble-predicate network (LAP-Net), decomposing visual relation detection (VRD) into three sub-tasks to tackle the long-tailed data distribution problem. |
|
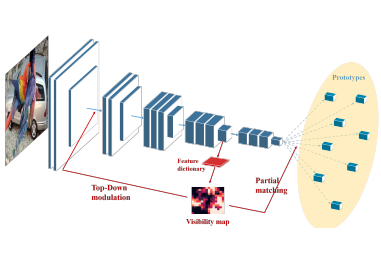
Mingqing Xiao, Adam Kortylewski, Ruihai Wu, Siyuan Qiao, Wei Shen, Alan Yuille ECCV 2020 Visual Inductive Priors for Data-Efficient Deep Learning Workshop paper We introduce prototype learning, partial matching and convolution layers with top-down modulation into feature extraction to purposefully reduce the contamination by occlusion. |
|
|
|
|
A deep learning and reinforcement learning library designed for researchers and engineers. ACM MM Best Open Source Software Award, 2017. I am one of the main contributors of its 2.0 version. GitHub / star (7000+) / fork (1600+) / contributors |
|
Umbrella research project behind Ideas in Excel of Microsoft Office 365 product. Intelligent feature announced at Microsoft Ignite Conference and released on March, 2019. Star of tomorrow excellent intern, 2019. project page |
|
|
|
Reviewer: ICCV, CVPR, ICLR, ICRA, RA-L, T-RO, T-Mech, TVCG
Workshop Co-Organizer: ICCV Workshop on Category-Level Object Pose Estimation in the Wild 2025 Student Committee Member: ARTS Volunteer: WINE 2020 |
|
|
|
Teaching Assistant:
Deep Generative Models, 2020, 2022 Guest Lecturer: Frontier Computing Research Practice (Course of Open Source Development), 2024 Introduction to Computing (Course of Dynamic Programming), 2024 |
|
|
|
Learning 3D Visual Representations for Robotic Manipulation,
National University of Singapore, Feb. 2025 Beijing Normal University, Shanghai Tech University, TeleAI, Jan. 2025 Tsinghua University, Johns Hopkins University, Carnegie Mellon University, Dec. 2024 University of Hong Kong, Nov. 2024 Unified Simulation, Benchmark and Manipulation for Garments, AnySyn3D, 2024 --- If you are interested in 3D Vision research, welcome to follow AnySyn3D that conducts various topics. Visual Representations for Embodied Agent, Chinese University of Hong Kong, Shenzhen, 2024 Visual Representations for Embodied Agent, China3DV, 2024 |
|
|
|
Best Poster Award, IROS ROMADO Workshop, 2025 Champion (team leader), ManiSkill-ViTac Challenge (presented at ICRA ViTac Workshop), 2025 Doctoral Consortium, CVPR, 2025 Doctoral Consortium (Oral Highlights), ICRA, 2025 Second Prize (top3), Outstanding Doctor Award of China Embodied AI Conference (CEAI), China, 2025 Shortlist (top40 among AI papers from 2022-2025), Youth Outstanding Paper Award of World AI Conference (WAIC), China, 2025 Nomination Award (top3), Outstanding Young Scholar Paper Award of China Embodied AI Conference (CEAI), China, 2025 Nomination Award, Rising Star Award of China3DV, China, 2025 ByteDance Scholarship, China and Singapore, 2024 Nomination Award (top8), ARTS Scholarship, China, 2024 National Scholarship and Merit Student (top1 in 50, CFCS), Peking University, Chinese Ministry of Education, 2024 Outstanding Student Workshop Speaker (top8), China3DV, China, 2024 Nomination, Apple AI/ML Scholar Fellowship, WorldWide, 2024 Research Excellence Award, Peking University, 2019, 2022, 2023 Excellent Graduate, Peking University, 2020 (undergrad), 2025 (Ph.D.) Peking University Scholarship Third Prize, Peking University, 2019 Star of Tomorrow Excellent Intern, Microsoft Research Asia, 2019 May Fourth Scholarship and Academic Excellence Award, Peking University, 2018 Bronze medal in National Olympiad in Informatics (NOI), China Computer Federation, 2015 First prize in National Olympiad in Informatics in Provinces (NOIP), China Computer Federation, 2013, 2014, 2015 |
|
Website template comes from Jon Barron
Last update: Nov, 2025 |